from matplotlib.colors import ListedColormap
from ml_utils.perceptron import Perceptron
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
s = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
df = pd.read_csv(s, header=None, encoding='utf-8') # dataframe
# print(df.tail()) # just to ensure that the data was loaded correctly
# Goal here is to restrict the task to a binary classification problem
y = df.iloc[0:100, 4].values # creates a np array (.values) from the species labels (4 == 5th column == species) of the first 100 rows
y = np.where(y == 'Iris-setosa', 0, 1) # 0 if setosa, 1 if versicolor (first 100 rows only have those two species)
# Goal here is to extract two fairly separable features from the same 100 rows of y
X = df.iloc[0:100, [0, 2]].values # 100 x 2 matrix that extracts two features: sepal length (0) and petal length (2)
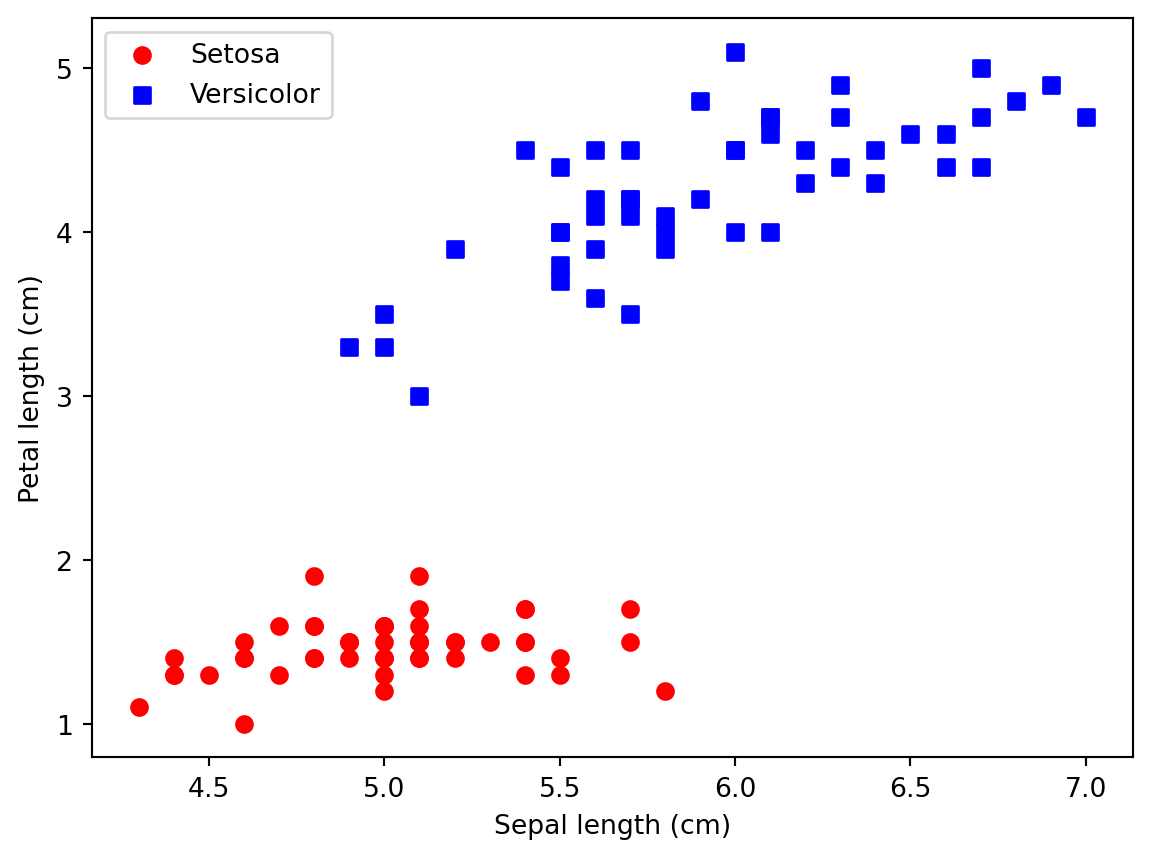
# Plot the two iris classes in the 100 x 2 matrix to visualize how separable they are before fitting a perceptron
# It's important that it's roughly linearly separable, which is when a perceptron would be a good choice
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label = 'Setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='s', label = 'Versicolor')
# Note that the x-axis here would be sepal length (because it's in column 0) and y-axis would be petal length (column 1)
plt.xlabel('Sepal length (cm)')
plt.ylabel('Petal length (cm)')
plt.legend(loc='upper left')
plt.show()
ppn = Perceptron(eta=0.1, n_iter=10)
ppn.fit(X,y) # train Perceptron on the Iris data subset
# Explore how the perceptron's training errors evolve over epochs.
# range(1, len(ppn.errors_) + 1) just creates the epoch numbers (x-axis)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o') # draws a point for each training epoch
plt.xlabel('Epochs')
plt.ylabel('Number of updates')
plt.show() # Converges after 6th epoch
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('o', 's', '^', 'v', '<')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
lab = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
lab = lab.reshape(xx1.shape)
plt.contourf(xx1, xx2, lab, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class examples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0],
y=X[y == cl, 1],
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=f'Class {cl}',
edgecolor='black')
plot_decision_regions(X, y, classifier=ppn)
plt.xlabel('Sepal length [cm]')
plt.ylabel('Petal length [cm]')
plt.legend(loc='upper left')
plt.show()